本文共 3690 字,大约阅读时间需要 12 分钟。
**zookeeper主要是对分布式系统提供服务的,ES集群,分布式文件系统,mysql主从复制,主要不是工作同一节点的都称为分布式系统
分布式系统:是一个硬件或软件组件分布在网络中的不同的计算机之上,彼此间仅通过消息传递进行通信和协作的系统。 **特征: 分布性、对等性、并发性(同时向外提供服务)、缺乏全局时钟、故障必然会发生(网络不是一直靠谱的)
面临的典型问题: 通信异常、网络分区、三态(成功、失败、超时)、节点故障
CAP:2000,7, Eric Brewer, ACM PODC (会议), 2002, MIT (麻省理工学院), Seth Gilbert, Nancy Lynch; 任何分布式系统只能完成CAP中的两个 P:分区容错性 CP:一致性,容错性 AP:可用性,容错性 保证可用,数据不一致,这样是没有意义的
 保证分布式系统的一致性多种协议: 2PC:2 Phase-Commit 2端式提交,整个数据留存袭来要分2步进行, 1.提交准备(请求和确认) 请求和执行 3PC:3 Phase-Commit 3端式提交, CanCommit可提交(判断集群中 哪些节点可以提交)->PreCommit预提交–>DoCommit Paxos 帕客所思协议(古希腊,天马paxos):Leslie Lamport,1990年提出,唯一公认在解决分布式方面,一致性问题,最有效的方法之一 但是现在有更简单的,能够为分布式系统提供服务协调和注册管理,2个方案,zookeeper,etcd,docker就用了etcd分布式中的各节点 zookeeper并不是paxos实现,而是Paxos 之上对整个协议变更,把实现思路做了变更。因为paxos真正用计算机算法实现非常难,
保证分布式系统的一致性多种协议: 2PC:2 Phase-Commit 2端式提交,整个数据留存袭来要分2步进行, 1.提交准备(请求和确认) 请求和执行 3PC:3 Phase-Commit 3端式提交, CanCommit可提交(判断集群中 哪些节点可以提交)->PreCommit预提交–>DoCommit Paxos 帕客所思协议(古希腊,天马paxos):Leslie Lamport,1990年提出,唯一公认在解决分布式方面,一致性问题,最有效的方法之一 但是现在有更简单的,能够为分布式系统提供服务协调和注册管理,2个方案,zookeeper,etcd,docker就用了etcd分布式中的各节点 zookeeper并不是paxos实现,而是Paxos 之上对整个协议变更,把实现思路做了变更。因为paxos真正用计算机算法实现非常难, 2PC:2 Phase-Commit 2端式提交,整个数据留存袭来要分2步进行, 1.提交准备(请求和确认) 请求和执行 有个问题,第一个发出请求的会被阻塞(木桶理论的,短板效应),最后请求完成了,才算全部完成,没有全部完成,是不足以请求下一阶段的
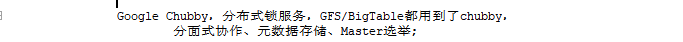
Google Chubby,分布式锁服务,GFS(google file system,hdfs hadoopfs)/BigTable(HBASE山寨了BIG table)都用到了chubby,(高可用分布式锁服务) 作用: 分面式协作、元数据存储、Master选举;
有一个公共的服务,多个节点运行的进程进行协调,节点之间要协调,节点之间需要发送消息的,但如果中间有节点挂了,就没有办法进行协调了, 因此这三个节点进行协调就不在彼此之间进行通信了,都与公共的存储进行通信,他们都能把自己的状态按周期同步到公共存储,每一个节点保证让其他节点看到相关信息,可以在公共存储保存一个数据节点,一旦这个服务器挂了,这个链接被终止时,存储随之被移除,其他节点 获取不到这个节点相关数据时,就认为这个节点不存在了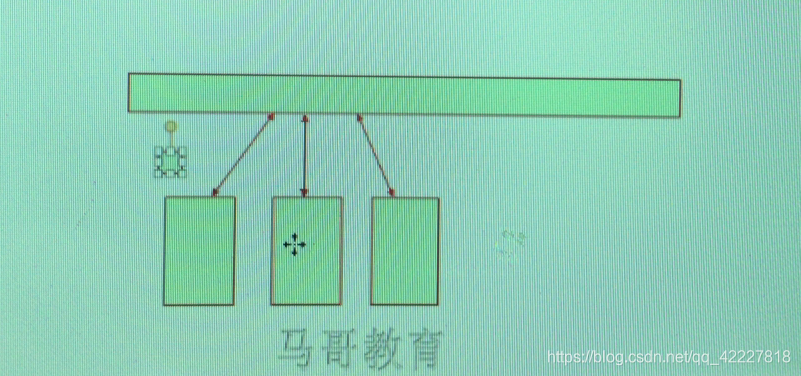 这个服务器自己还支持主节点选取功能,公共存储服务,也需要高可用,一般是基数,三个以上节点来保证自己挂了,其他继续服务
这个服务器自己还支持主节点选取功能,公共存储服务,也需要高可用,一般是基数,三个以上节点来保证自己挂了,其他继续服务 山寨chubby就是zookeeper
HDFS/HBase, Zookeeper zookeeper是一个开源的分面式协调服务,由知名互联网公司Yahoo创建,它是Chubby的开源实现;换句话讲,zk是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于它实现数据的发布/订阅、负载均衡、名称服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列;
HDFS+mapreduce=hadoop hbase山寨big table 在hdfs上提供列式数据服务的
puppet在同步更新是一个个来的,zk可以通知所有订阅者
基本概念: 集群角色:Leader, Follower 评, Observer 观察员(zk至少三个节点,是个集群,一般是2个follower,一个leader) Leader:选举产生,提供读/写服务; Follower:参与选举,可被选举(leader挂了,可以当master),读服务; Observer:参与选举,不可被选举(无法成为master),提供读服务;

数据节点(ZNode):即zk数据模型中的数据单元;zk的数据都存储于内存中,数据模型为树状结构(ZNode Tree);每个ZNode都会保存自己的数据于内存中; 节点有两类 持久节点:仅显式删除才消失 临时节点:会话中止即自动消失(zk客户端与zk建立的会话链接)
数据节点有版本
 多个分布式系统可能用一个zk,所以zk需要把他们隔离开来 ACL:ZK使用ACL机制进行权限控制 CREATE, READ,WRITE,DELETE,ADMIN
多个分布式系统可能用一个zk,所以zk需要把他们隔离开来 ACL:ZK使用ACL机制进行权限控制 CREATE, READ,WRITE,DELETE,ADMIN  事件监听器(Watcher): ZK上,由用户指定的触发机制,在某些事件产生时,ZK能够将通知给相关的客户端; 节点向zk注册监听器,一旦数据发生变化,zk可以立即将变化通知给注册监听器的相关节点,然后大家过来选新的村长 所有分布式节点都可以基于zk来完成选举,协调,发布订阅,zk实现,是靠zk的专门协议
事件监听器(Watcher): ZK上,由用户指定的触发机制,在某些事件产生时,ZK能够将通知给相关的客户端; 节点向zk注册监听器,一旦数据发生变化,zk可以立即将变化通知给注册监听器的相关节点,然后大家过来选新的村长 所有分布式节点都可以基于zk来完成选举,协调,发布订阅,zk实现,是靠zk的专门协议 ZAB协议:Zookeeper Atomic Broadcast,ZK原子广播协议;zab协议完成,各节点参者间的leader选举 保证leader崩溃时可以重新选举出新的leader,还要保证数据完整性的, 支持崩溃恢复机制, 所有事物请求由leader处理,其他服务器,follow,obsrv,只提供读 ZAB协议中存在三种状态: (1) Looking, (2) Following, (3) Leading
ZAB协议:Zookeeper Atomic Broadcast,ZK原子广播协议;zab协议完成,各节点参者间的leader选举 保证leader崩溃时可以重新选举出新的leader,还要保证数据完整性的, 支持崩溃恢复机制, 所有事物请求由leader处理,其他服务器,follow,obsrv,只提供读 ZAB协议中存在三种状态: (1) Looking, (2) Following, (3) Leading 当用户发出写请求,是发给zk 的leader,leader收到信息后,把这个修改的请求转为一个提案,向zk的集群进行广播,修改数据是否同意,下面的follower举手同意,过半数的时候,把数据更新到源数据
zk的所有事物,都要由leader来接受和处理,客户端无论连接在哪个zk节点上,如果不是一个leader的话,应该把这些信息转给leader,leader会把每一个客户端请求转为一个提案向队员的当前集群中进行广播,在收到过半数的follower投票的时候,将会确认此操作,并将这个结果广播给其他的follower而后完成提交

ZAB协议中存在三种状态: (1) Looking, 每一个zk节点刚启动的时候,要找leader,(选举过程,looking过程) (2) Following,已经有leader (3) Leading leader节点的状态 每一个节点都有可能在三个节点进行转换,zk启动时,所有节点都是默认Looking状态,然后整个集群会尝试选举一个leader,被选举的切换为 leading,其他的切换为following 选出leader以后,zab协议将进入原子广播阶段,leader数据需要打包给follow节点,leader节点和follower节点,必须使用心跳检测机制,去检测每一个follower是不是,处于正常状态的,这种检测机制,相当于follower不断 在集群中某个数据节点更新数据版本,如果一直更新,leader就认为 他们是正常的,如果超过时间,一个follower没有在更新自己的指定信息,就认为失去连接。如果失去的是leader,大家都转换为looking,就提案自己当leader 选举,发布,同步,广播等阶段
转载地址:http://kjkgn.baihongyu.com/